|
| Sunday, November 15 TUTORIALS |
|||
|
Tutorial 1:Overview and Comparison of SDN Standards |
Adrian farrel, Routing Director, IETF |
|
Software Defined Networking (SDN) is a prevalent marketing term that attempts to embrace a set of core principles. These are typically identified as the separation of the data plane and control plane, a programmatic interaction with the network, network abstraction, and the use of a functional component called a Controller to exert direct control on network resources. Multiple technologies exist that meet these objectives and conform to the requirements and architecture implicit in the very definition of SDN. These technologies include established standards-based approaches such as the Path Computation Element (PCE) and the Interface to the Routing System (I2RS). There are also new emerging standards like Service Function Chaining (SFC) and Segment Routing (SR). Recent advances in protocol specifications to separate control and forwarding include Open Flow (OF), Protocol Oblivious Forwarding (POF), and P4 (Programming Protocol-independent Packet Processors). Operators and vendors must choose between forwarding and control plane implementation technologies. Criteria for such decisions may include a preference for one of many implementation design axes: centralised to distributed, micro-flow to aggregated-flow, reactive to proactive, virtual to physical, stateless to stateful, and fully-consistent to eventually-consistent. In many cases a further commercial, operational, and implementation decision is required to determine the deployment of these technologies: open source, closed open source, or property software. This tutorial outlines many of the SDN architectures and technologies available today and describes how they relate to each other. Where possible we evaluate and compare multiple technology and deployment options, summarising current art, challenges/gaps, opportunities and next steps. It is, however, not our intention to make a decision for you since your requirements will all be different and different options will suit different scenarios. |
|||
|
Tutorial 2: Self-Configuring and Self-Organizing Networks |
Kireeti kompella, Juniper Networks |
|
This tutorial will explain the concepts of self-organizing networks and show how such networks can also be self-configuring. These notions are common in some parts of the network, especially in mobile networks, but can (and should) be applied much more widely. The goal is to decrease operator intervention, increase reliability, improve responsiveness, enhance efficiency, and generally improve end user perception of services. Some components of self-organizing and self-configuring networks include autodiscovery mechanisms; detection of changes in topology, usage — more generally, network telemetry; adaptive algorithms; and steering policies. The tutorial will offer more details on these and other components, as well as say how they interact. Finally, it will offer up some directions for future research. |
|||
|
Tutorial 3: Virtualization Technology and usage of Virtualization for Security Apps |
dennis moreau, VMware |
|
TBA |
|||
|
Tutorial 4: Internet of Things (IoT): Access, & Infrastructure |
||
TBA |
|||
| Monday, November 16 TECHNICAL SESSIONS |
|||
|
Introduction |
bijan jabbari, Isocore |
|
|
|||
|
Opening Remarks |
Dave mcdysan, Verizon |
|
|
|||
|
Keynote Speech |
TBA |
|
|
|||
|
Invited Talk |
TBA |
|
|
|||
Break & Exhibits |
|||
|
YANG-Based Service Models for Services over MPLS Networks |
, Old Dog Consulting |
|
YANG models are increasingly the mechanism of preference for configuring devices and networks. They are used in the south-bound interface from a network controller to the device for specific provisioning in SDN systems, and they are used proposed for a south-bound interface between a controller or orchestrator and a control-plane enabled network in a hybrid SDN architecture.
|
|||
|
Experiences in Building an Open Management Plane |
anees shaikh, joshua george, Google |
|
The state-of-the-art in network management remains relegated to proprietary device interfaces (e.g., CLIs), imperative, incremental configuration, and inflexible, legacy protocols (e.g., SNMP). The rising adoption of SDN has shown the benefits of well-defined, programmable APIs to the data and control planes, but these capabilities are lacking in the management plane where there is a significant opportunity for automation and increased operational efficiency. In this talk, we will share our experience in leveraging the collective expertise of network operators to build standard, open-source, operations-centric models that enable declarative configuration and streaming telemetry. This new streaming model for monitoring the network overcomes the scaling limitations of legacy mechanisms, and offers new flexibility in how management systems interact with network elements. We describe the efforts of a number of global-scale network operators to collaborate on the development of common APIs for the management plane based on data models, with a focus on network configuration and monitoring. The OpenConfig working group is the first industry-wide initiative driving an open, software defined network configuration and management plane that allows programmatic network operation. By working closely with multiple vendor partners, we are enabling new and existing platforms with native support for the next generation open management interfaces. |
|||
|
Carrier DevOps Orchestration |
Alex-henthorne iwane, Qualisystems |
|
This talk will discuss what DevOps orchestration looks like for carrier, and how it must adapt to telecom and networking realities to act as the companion operational movement to SDN/NFV network architecture. A case study with real world results will be shared to illustrate how DevOps can transform complex carrier services to make teams more productive and innovative. |
|||
|
Service and Policy Aware SDN Management and Orchestration (MANO) |
Packet Design |
|
Networks today run many different services and applications. These services have different performance and policy requirements from the network than the services of the last decade. For example, one service provider provides short delay paths to select set of high-revenue financial customers and it needs to measure delay across the links in its network and may segregate these customers' paths from the rest of its customers. Another major service might be the over-the-top video, such as NetFlix and YouTube. This service has a video quality requirement, and if not met, may lead to customer churn. The service is very adaptive and can tune its bandwidth requirements to available resources. In this case, the SP may provision for optimum video quality under normal network conditions and may want to tune the video quality down under link and router failures. This enables the service provider not to over provision its network too much for handling failures. These, and many other services, are now carried over the same network. As a result, SDN MANO needs to become service aware by provisioning these services end-to-end, from the access and aggregation networks where necessary VRFs, access-lists are setup, to WAN where paths that satisfies these performance requirements are setup. In this talk, we will give an overview of some of the new protocol and open-source developments, such as IETF’s NETCONF/YANG, I2RS policy associations, and PCEP, and how they can be orchestrated together to achieve this end-to-end service activation. However, protocol developments alone solve only part of the puzzle. To gain maximum network efficiency, we need extreme topology and performance telemetry from different layers of the network and apply analytics algorithms to find resources in the network to run these services even under heavy load. Hence, we will also illustrate how we overlay different traffic-matrices, one for each service class, on top of each other with their own separate optimization algorithms in order to yield optimum multi-service delivery network. |
|||
Lunch & Exhibits |
|||
|
Integrating Service Provider Networks and Data Centers networks |
Deutsche Telecom |
|
Many service providers are currently building data centers for provide access to virtualized network functions. The integration of those data centers into an existing carrier network is one of the main challenges which need to be addressed. With NFV there is the need to provide an end to end view and orchestration which not only covers the data center but also spans the service provider network and the data center network. This presentation will cover different options for integrating DC and SP network and addresses the following topics: |
|||
|
Sensors, telemetry and analytics in large data center networks |
Vijoy pandey, Google |
|
The presentation will introduce the unique needs of network telemetry and analytics in large data center fabrics. We start with outlining an intent based declarative approach to modeling greenfield or brownfield fabric topologies given a set of capacity, topological and traffic constraints. We then describe a pipeline for generating and analyzing network sensor/telemetry data - specifically touching upon 3 analytics applications - performing topology verification, routing consistency, and end host granular reachability analysis. The talk will focus on the operational experiences gained in deploying these systems at scale. |
|||
|
Seamless Overlay Mobility for the Hyper-Elastic CloudThe Roles of Open Daylight, Open Stack and NFV/SFC |
Luyuan fang, Microsoft |
|
As the demand for cloud services continues to grow at an explosive rate, the next generation cloud has to reach a new level of scale and elasticity. The virtualized overlay network layer has to scale to support millions of Virtual Networks (VNs), connecting hundreds of millions of Virtual Machines (VMs) and Virtualized Network Functions (VNFs). In addition to scale, elasticity is essential for cloud providers to manage capacity effectively in their Data Centers (DCs), improve service velocity, increase availability, and give customers even more dynamic access to compute, storage, and network resources. Scalable and lossless VM and VNF mobility is the key capability that we need to achieve in order to enable this all-new level of elasticity. Last year, we presented Hierarchical SDN (HSDN), a solution to scale the Data Center and cloud underlay network infrastructure to support tens of millions of physical endpoints at low cost. HSDN is an architectural framework that applies to both control and forwarding planes, and has some unique, highly desirable properties. In particular, HSDN radically simplifies establishing and handling tunnels and can operate with all paths in the network pre-established in the forwarding tables. In this presentation, we apply the HSDN principles to the overlay network layer to achieve this all-new desired level of elasticity at scale. We present a novel overlay mobility scheme that takes advantage of the unique properties of HSDN to achieve seamless and lossless VM and VNF migration at scale. We then use hierarchical partitioning in the overlay network to scale the updating of the overlay reachability information, as required to support migration, and dramatically improve convergence. |
|||
|
DC architectures with Overlays and Underlays |
azhar sayeed, Cisco |
|
Overlay networks are popular for DC architectures because they provide network infrastructure independence – but they also provide a number of challenges – being out of sync with the underlay means the overlay has no information when the underlay changes – this can result in latency challenges which in turn has an impact on application performance. With hosted applications being the name of the game and increasing packet processing capabilities with general purpose compute, the key question is can overlay networks really provide the full suite of capabilities like an integrated stack would? If not then what is the optimum approach and can SDN provide an answer to this mix. This presentation compares this existing overlay technologies, highlights their differences and explores solutions and optimizations wrt to overlays and underlays. It also looks at how some Sps are building Scale-up clouds to host mission critical applications and what impact does an overlay have to that model |
|||
Break & Exhibits |
|||
|
Transformational Opportunities in Cybersecurity: Leveraging Network Virtualization and Softwarization of Security Controls |
Dennis moreau, VMware |
|
Security breach rates are increasing, with associated losses approaching $445B. Over 90% (Gartner) of these breaches are associated with misconfiguration, driven by security management complexity. This complexity is rooted in the system, network and control architectures underpinning traditional datacenters and hosting fabrics. Additionally, rapidly morphing threats, shifting business need, evolving regulatory restriction, dynamic workload footprint and emerging technologies, all act to exacerbate this management complexity. The emergence of SDN, NFV and security control softwarization presents the opportunity transformationally improve cybersecurity.
|
|||
|
Rights and Responsibilities for Connected Citizens |
Monique morrow, Cisco |
|
We are moving from a hobbyist form of being connected as humans exemplified by the popularity of personalized wearables designed to monitor your level of fitness to one where the notion of the Internet of Bio-Nanothings [IoBNT] designed to enable applications such as intra-body sensing with implications to molecular communications. The amount of information that is transmitted publicly should evoke questions as to security-safety and privacy. Do we become our own human API? What must be your rights and responsibilities as the quantified self? This presentation seeks to undertsand societal and ethical implications to the quantified self; and to provoke further research on this topic. |
|||
|
Defending against Distributed Denial of Service Attacks in Distributed and Virtualized Network Systems |
andy zhigang, Huawei |
|
Historically, denial of service (DoS) attacks have been mitigated by a combination of deep packet inspection and traffic policing at the network edges. Distributed denial of service (DDoS) attacks have made this harder because attacking traffic can enter the network from a large number of sources simultaneously. In order to protect against DDoS, policing has to be performed closer to the target (the attacked node in the network) or must rely on sophisticated and coordinated traffic monitoring across the network.
|
|||
| Tuesday, November 17 TECHNICAL SESSIONS |
|||||||||
|
Carrier Grade SDN Requirements, Gaps, and Standardization |
andrew malis, Huawei |
|||||||
This talk will describe why carriers need SDN, their SDN requirements, a carrier SDN-based network architecture, addressing the requirements, and related standardization in the ONF and IETF.It has been over 17 years since the formation of the MPLS Work Group and 18 since many of the fundamental tenets of its architecture were conceived. Over that period MPLS has evolved in many directions encompassing Traffic Engineering, L2 VPNs, L3 VPNs, EVPN, Pseudowires, BGP scaling, and MPLS-TP Now Segment Routing with control via SDN is being deployed. Other applications of SDN to MPLS are also being developed. This talk will cover the founding principles of MPLS that have allowed MPLS to evolve and morph in so many ways. It will explore how technology changes in processor speeds and cache sizes, frame size and link speed, and the scalability of IGPs and BGP have enabled ideas that were only dreamed of (if even concieved) in 1996 to be realized. In particular it will explore SDN control of MPLS and Segment Routing.
|
|||||||||
|
NFV Enabled Network Node Architecture on OpenFlow Software Switch |
Hitoshi Masutani, NTT Labs |
|||||||
In carrier networks, easy deployment of new network functionalities and automation of network operation are becoming increasingly important to rapidly provision network services for a variety of user demands. Network Function Virtualization (NFV) and software-defined networking (SDN)/OpenFlow are attractive concepts that meet these requirements. We present our NFV-enabled network node architecture leveraging SDN/OpenFlow. We also introduce a virtual BRAS (Broadband Remote Access Server) prototype using Intel DPDK as high performance throughputs.
|
|||||||||
|
Virtualized Voice Service Testbed on Public Cloud |
Douglas freimuth, IBM |
|||||||
We have demonstrated a virtualized voice service built on the OpenStack cloud operating system running on IBM SoftLayer public cloud. The IBM Software Defined Platform was used to deploy a Session Border Controller (SBC) and IP Multimedia Subsystem (IMS) core. The deployment has the open characteristics sought for an NFV environment. We will discuss the components used for the open source IMS core and third party SBC. We will discuss the IBM Software Defined Platform and policy framework used in the deployment of the workload. Finally we will discuss the SoftLayer Public Cloud that we used to build the testbed and the network design for the virtual voice service.
We demonstrated softphone registration, call completion and scaling components of the voice service. We relate the experience of using the SoftLayer Public Cloud as a platform to test and develop NFV services. |
|||||||||
|
Benchmarking for SDN and NFV |
Gurpreet singh, Spirent |
|||||||
Is your NFV infrastructure ready for carrier grade deployment? |
|||||||||
Break & Exhibits |
|||||||||
|
Unified Forwarding using Segment Routing |
mohan nanduri, Microsoft |
|||||||
Software Defined Networking (SDN) paradigm offers flexibility to the operators and service providers in provisioning and managing their networks. Segment Routing (SR) technology can enable networks to achieve scalable SDN and traffic engineering solutions. In this presentation, we will show usage of SR technology and protocols with SR enhancements such as BGP-LU and BGP-LS in an large scale network. Our architecture, design and standard-compatible approaches aim to offer efficient and scalable SDN solutions for core, intra- and inter-datacenter networks. The presentation will discuss our challenges and observations drawn from a real-deployment. We will highlight our engagement and collaboration with vendors in advancing this technology. |
|||||||||
|
Segment Routing Unified Forwarding Plane - DC and Agile Carrier Ethernet Use Cases |
santiago freita, Cisco |
|||||||
During this session we will present how Segment Routing is used to unify the forwarding plane between Data Centers, WAN and Carrier Ethernet architectures. Use cases and customer motivations will be covered, together with the technical innovations required to deliver on this vision. This session will be delivered together with an operator* to bring the perspective of a Service Provider and an Enterprise consuming the service. *What is the goal of this session?* Demonstrate how a Segment Routing based unified forwarding plane architecture address current and emerging use cases that benefit from an integration between Data Centers, WAN and Carrier Ethernet architectures. *How will the session help the participants or their customers solve a problem or meet a need?* It will provide use cases that the attendees can relate to, and that are relevant for current and future needs. *The operator to co-author the session has been identified but is not yet ready to be publicly mentioned. |
|||||||||
|
Segment Routed Traffic Engineering |
Siva sivabalan, Cisco |
|||||||
|
|||||||||
|
Case Study: Segment Routing using WAN Automation Engine (WAE) to plan and deploy nextgen IP networks |
Guilherme tuche, Cisco |
|||||||
During this session we will present how we can use Segment Routing to |
|||||||||
Lunch & Exhibits |
|||||||||
|
Policy Routing via SDN and Segment Routing |
George swallow, Cisco |
|||||||
|
|||||||||
|
EVPN as a stepping stone to SDN |
Bruno rijsman, Juniper Networks |
|||||||
We are seeing a great deal of interest in EVPN, particularly in the data centers. It allows our largest data center customers to build massive layer-3 data center fabrics, while still providing a layer-2 service to their customers. It also provides multi-tenancy and sophisticated policy control mechanisms. EVPN can be viewed as a traditional distributed control plane protocol where each device is managed individually. In the talk I will make the argument that there is a natural evolution from EVPN to full SDN. With EVPN, it is possible to define very sophisticated policies such service chains between tenants. I will point to the recent IETF drafts that describe in detail how this can be achieved with clever manipulation of the Route Targets (RTs), Route Distinguishers (RDs), and next-hops. However, in reality, it quickly becomes infeasible to do such configuration manually. Here is where the SDN controller comes in. It allows you to define the policies at a high level of abstraction. In the management plane, the SDN controller “compiles the high level policies into low level configuration of RTs, RDs, and next-hops”. In the control plane, the RD acts as a super-intelligent route-reflector, that manipulates the traffic using next-hop and MPLS label manipulation. Also, the SDN controller is tightly integrated with the virtualization orchestrator (e.g. OpenStack) to dynamically create overlay tunnel endpoints (VTEPs) in the hypervisor when needed. Finally, the SDN controller adds a telemetry and analytics dimension. Thus, we see that EVPN can be viewed as an migratory intermediate step between traditional MPLS-VPN protocols towards full SDN. |
|||||||||
|
Achieving Resilience in Ring Networks Using MPLS |
||||||||
Rings are special — the simplest topology that offers resilience — and they are nearly ubiquitous. Current approaches to resilience on rings with MPLS are inefficient and complex. This talk offers a different way to achieve resilience in rings with MPLS; it also shows how some of the principles of Self-Organizing Networks can be used to simplify configuration and operation of MPLS in rings. The approach is open and standards-based. The talk motivates the new paradigm (called Resilient MPLS Rings), and offers technical details on how it works. The main idea is similar to BLSR, but operating at the packet (MPLS) layer. This involves IGP and RSVP-TE extensions. A status update on standardization will also be presented. |
|||||||||
|
Network telemetry: rethinking network management as a big data problem |
shelly cadora, santiago alvarez, Cisco | |||||||
This talk will review the emerging requirements for streaming telemetry and outline open questions and interesting issues around this nascent technology. The network infrastructure measures and senses vast amounts of interesting data, but that data has never been simple to collect. New use cases and new tool chains for network monitoring can consume far more data than we can extract using conventional methods like screen-scraping and SNMP. Streaming telemetry is a relatively new paradigm for getting large amounts of data off the network as quickly as possible. |
|||||||||
Break & Exhibits |
|||||||||
|
Design and Implementation Challenges in Modeling MPLS/TE for Large-Scale Network Operations |
ina minei, Google |
|||||||
| The increased interest in providing programmable interfaces for network operations has led to a growing number of data models being developed to describe many elements of the network. These data models, most often written in the YANG data modeling language, are intended to define an API for the network to replace operations traditionally done manually or scripted through CLIs. Given the importance of MPLS and traffic engineering in many large networks, it is clear that having YANG data models for MPLS is crucial for enabling automation and programmability in key parts of the network. In this talk, we share our experiences in developing a programmable interface for managing MPLS and traffic engineering in global-scale multi-vendor networks, with support for both configuration and operational state monitoring. We discuss the challenges in designing a complex data model that is vendor neutral and operations-centric, while also being realizable across major platforms. We describe our efforts to represent existing LSP configurations using these models as we transition our management software away from platform-specific tooling to vendor-neutral open interfaces. Finally, based on our ongoing engagements with major vendors, we highlight some of the key areas of implementation differences between vendors, and how these differences can be managed in the models. |
|||||||||
|
Flow Mining and Model Predictive Control for Macroflow-based Traffic Engineering |
kohei shiomoto, NTT R&D |
|||||||
Carriers are seriously considering what they should design and construct for future networks and how they should operate them. They expect that Software-defined networking (SDN) will play a key role in operating future networks because it allows them to implement their own management policy by separating the control-plane from the network elements. [1] Y. Takahashi, K. Ishibashi, N. Kamiyama, K. Shiomoto, T. Otoshi, Y. Ohsita, and M. Murata, "Macroflow-based traffic engineering in SDN-controlled network," iPOP 2015, T3-1, Okinawa, Japan, April, 2015 |
|||||||||
|
Traffic optimization (Hadoop’ MapReduce traffic) to enable large flow re-engineering in Software Defined Data Center |
||||||||
Software defined network separates control functions from underlying network and is enabling enterprises to build manageable data center to support big data processing. Big Data frameworks has emerged as an important platform for data intensive distributed computing, real-time analysis and enables actionable intelligence for Software Defined Networks.
|
|||||||||
| Wednesday, November 18 TECHNICAL SESSIONS |
|||
|
Photonic Nation- A Vision for a Virtualized Photonic Communication Infrastructure- How to Get Ready for the Next Wave of Service Requirements |
Lieven Levrau, Alcatel-Lucent |
|
|
This abstract describes the vision for an agile photonic communication infrastructure capable of supporting a range of Information and Communications Technology services offered by Tier1 operators, alternative Service providers, and research and education networking users. The envisioned solution provides virtualized connectivity resource management architecture, enabling the independent administration of each of the users allocated resources; and a fully agile and dynamic photonic network layer.
To achieve the goal of a widespread nation-wide, virtualized communication resource, the deployed solution must meet several requirements, including:
The presentation will analyse and discuss the fundamental building blocks of the architecture, and illustrate the benefits of the architecture, these include:
Advanced network research increasingly requires testbeds, deployed at scale, to fully realize and evaluate novel network concepts. Constructing such large scale testbeds - and providing the security, privacy, access to key network switching and forwarding nodes, and control by the user (research team) - pose technical, administrative, and budgetary hurdles that degrade, delay, or completely block advances in network technology, best practices, and/or distributed applications. GEANT, the pan-European research network, is investing in advanced automated service technologies that can create and manage such distributed experimental environments easily and efficiently. The GEANT Testbeds Service (GTS) is a production GEANT capability that provides the user with virtualized network resources such as computational/end system platforms, virtual circuits, and both experimental (OpenFLow) and conventional switching/forwarding elements in a user defined and user controlled distributed environment spanning the European footprint. GTS targets the software defined networking and global network virtualization research communities as they explore these emerging topics, and is working collaboratively with other similar initiatives toward a common global approach to such services. This talk will provide an overview of the GTS service architecture, its current development and deployment status, and the roadmap for the next several years. |
|||
|
Development of All-in-one Control Equipment for an Optical Packet and Circuit Integrated Network |
||
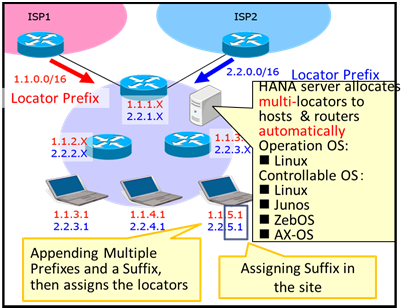
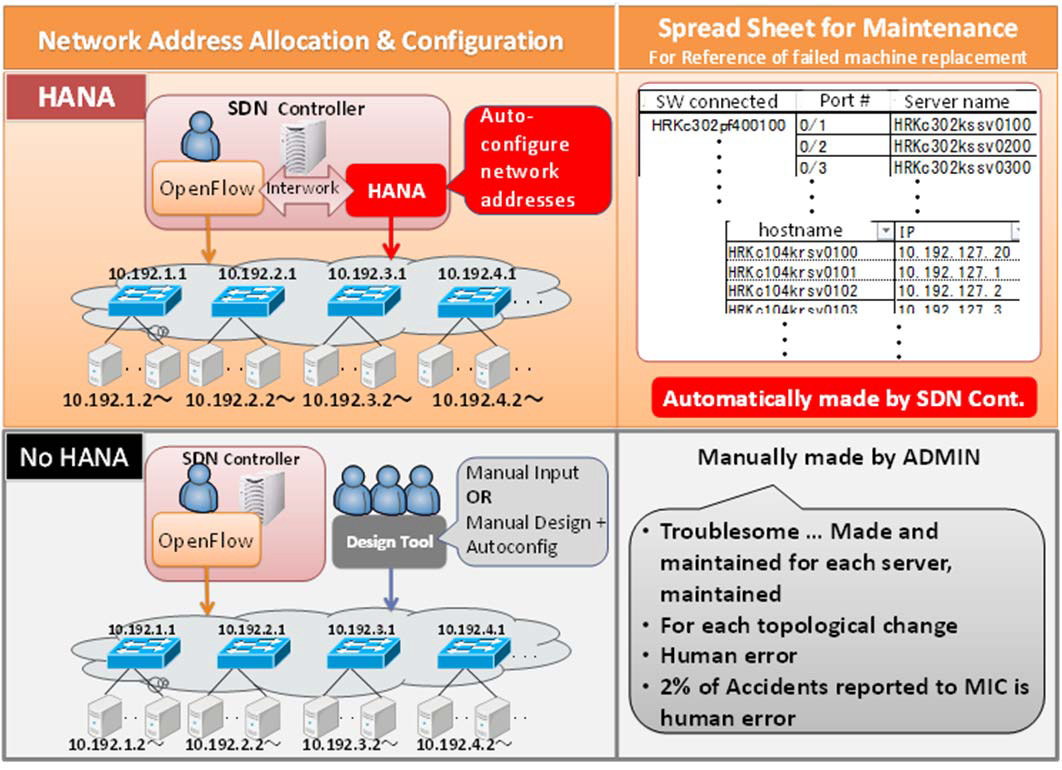
Hierarchical and automatic number allocation (HANA) [1][2] is an
Fig. 1. HANA Overview.
|
|||
|
Nationwide Demonstration of Software Defined Optical Transport Networking via Multi-domain Orchestration |
Xiaoyuan cao, KDDI Labs |
|
|
|||
|
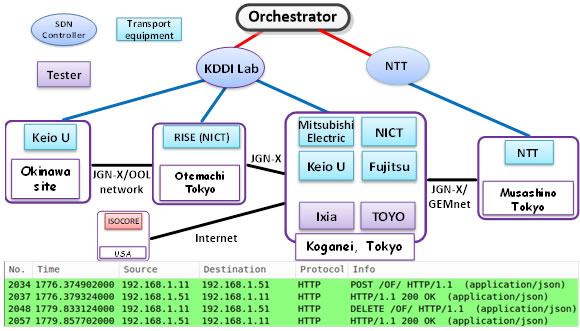
SDN controlled Virtual OLT Migration trial over JGN-X testbed network |
YOshihiro isaji, Keio University |
|
Recently, user demands for network services have been diversified. Especially users expect QoS which enables users to continue using high priority communication services even when the network cannot continue to accommodate all services due to a disaster, and scheduled service which enables users to communicate by paying only for the time and bandwidth they use. Operators’ revenue will increase by providing these attractive services. In order to put these services into practice, operators’ networks need to realize both high reliability to continue services when faults occur, and global optimization to accommodate various traffic for each user and time by efficiently utilizing limited network resources, such as network nodes and links. Previously two techniques, protection switching and rerouting, have been used to change each route. Protection switching realizes high speed switching to protection route registered by the operator in advance, within 50msec when a fault occurs. However, protection switching has issues on inefficiency of network resource usage due to resource allocation of protection routes, and on service disruption when faults occur both on working and protection routes due to a disaster. On the other hand, rerouting is a technique to change a route by re-computing the most appropriate route. However, rerouting has issues on difficulty in utilizing network-wide resource usage efficiently since rerouting is performed for each route, and on difficulty in high speed route change since re-computing is performed after a trigger happens, which may result in service disruptions. We propose packet transport network system where centralized control is performed by SDN orchestrator and it dynamically assigns network resource to globally optimize the resource usage efficiency (Fig. 1). The proposed network system is characterized by its SDN orchestrator which manages multiple logical planes. A logical plane is defined as a group of logical routes and their assigned bandwidth, which operators register in advance. In order to apply the most appropriate logical plane to the network, SDN orchestrator has NW analysis function and logical plane control function. NW analysis function monitors and analyzes network status and selects the most appropriate logical plane. Based on the information of time, node failure and loss of services (1), NW analysis function selects the most appropriate logical plane in terms of bandwidth assurance, connectivity of user service, resource usage, and power consumption (2). On receiving a trigger (3) from NW analysis function, logical plane control function (4) send logical plane switch requests to network nodes (5). When a disaster happens in the network and the loss of services number exceeds pre-configured threshold, SDN orchestrator selects and switches logical plane in a short time, so that high priority services’ communication routes bypass node failure point. In this way, the influence of disaster on high priority services is minimized. As a result, operators can continue providing high priority services by effectively utilizing limited resources. On the other hand, when a operator provides scheduled service, SDN orchestrator applies logical plane to the network so that unused devices (for example, interface cards) can be shutdown for power saving.
|
|||
Break & Exhibits |
|||
|
Abstract-hop Constrained Routing - A Hybrid Path Computational paradigm |
Nick slabakov, Juniper Networks |
|
In the distributed path computational model, the computation is carried out at the head-end network element. This is done based solely on the head-end network element’s view of the network-state. In the centralized path computational model, the computation is carried out by an external Path Computational Element (PCE) that maintains a global view of network state. Each of these traditional computational models has well-documented benefits and drawbacks of its own. This presentation will introduce a new computational paradigm that leverages the benefits of both the traditional computational models and will discuss in detail the motivation behind using this paradigm. This new hybrid computational paradigm involves having the centralized computation element compute the path in terms of a sequence of abstract hops and then letting the head-end network element take care of computationally expanding the abstract hops in the path. In order to facilitate abstract-hop constrained routing, abstract views of the TE Topology must be created and computation needs to be done off of the resulting abstract topology. In the mechanism detailed in this presentation, a set of abstract regions are defined where each abstract region represents a group of routers that satisfy a logical combination of certain link/node attributes, say admin group, SRLG, etc. The centralized computation is done off of the abstract view and hence the path generated by the centralized computation engine results in a sequence of abstract hops. These abstract paths are then handed over to the head-end node which takes care of translating these into actual paths using its view of the current network-state. This presentation will discuss in detail the various tools that are needed to facilitate this notion of hybrid computation. The presentation will also take a close look at an implementation that enables abstract hop definition, views the routers in the topology as belonging to various abstract hops and uses the hybrid computational paradigm to compute and set up LSPs in the network. |
|||
|
Benchmarking for PCE |
Rajesh rajamani, Spirent |
|
PCEP provides an evolutionary approach to provide centralized SDN
|
|||
|
Evolving the operation of network devices |
Santiago alvarez, Cisco | |
This talk describes new paradigms and tools available for the operation of network devices. Network management traditionally required high levels of human intervention that lead to long-cycles to make any changes to a network. The requirement for a more responsive network infrastructure has led to new approaches to configuration management, network monitoring and software management. These new capabilities enable a higher level of network automation that leverage some of the lessons learned from the operation of large compute resources. |
|||
|
Transport SDN Controller for multi-domain, multi-layer, multi-vendor networks with a network abstraction mechanisms |
naoki miyata, NTT Communications |
|
Software-define networking (SDN) allows service providers to realize the network programmability, the OPEX/CAPEX reduction, and the short lead-time service delivery. It can be applied to our backbone transport networks. Network elements for SDN are becoming available in the market and open source controllers to manage transport networks have been developed. They increase the feasibility of realizing Transport SDN. The characteristics of transport network are multi-layer, multi-domain and multi-vendor. First of all, multi-layer means that our transport networks use multiple technical layers, such as WDM, OTN, MPLS and so on. Secondly, it has an access network domain to connect subscribers to service providers, an aggregation network domain to route subscriber’s traffic and a core network domain to provide highly aggregated connections. We administrate them in different manners. Finally, multiple vendors’ products are introduced for with respect to each layer and each network domain. Its operations are currently segmented and specifically optimized. The problem of our transport networks is how we achieve the agile and low-overhead operations required by the subscribers and cloud applications. In the existing situations, we spend long time and cost to introduce vender-specific network operating systems and service-specific OSS/BSS and educate operators in order to introduce new network equipment and provide new services. In addition, the specific optimization causes inefficient operations in total. Our approach to solve the problem is to develop the SDN controller which can control transport networks in a lump. Two points are required to consider. First point is to abstract multi-layer, multi-domain, and multi-vender networks. Second point is the scalability and high-availability, which is enough to entrust the controller to manage our backbone networks. We will present the use cases and PoC of transport SDN.
|
|||
Lunch & Exhibits |
|||
|
Intelligent Software Defined Network Architecture |
Huaimo chen, richard li, Huawei |
|
Following the concepts of Software Defined Networks (SDN), a number of key architectures have been proposed for a SDN controller to control a network and manage the resources of the network. Most of the architectures typically rely on a centralized approach but in some cases a hybrid approach may also worthwhile. However, the existing SDN architectures proposed have some weaknesses. For the SDNs using open flow based technologies, every forwarding node in the network must be open flow capable. In addition, there must be a connection or session between the central SDN controller and each forwarding node in the network. For segment routing (SR) based SDN, it is required that every forwarding node in the network support the maximum depth of label stack that a SR data packet may have. Some extra labels in a data packet constitute a big overhead. Moreover, the SDN controller must have a connection or session to every edge forwarding node of the network. In brief an “intelligent” SDN must be capable of addressing the weaknesses in open flow and SR based SDNs. It should be forwarding technology agnostic and be capable of integrating with a range of existing forwarding mechanisms, as well as future forwarding technologies. The intelligent SDN controller should utilize the strengths of both central and distributed control mechanisms. This article will present an intelligent SDN, in which the SDN controller can just connect to one or a few of any forwarding nodes in the network. It is not required that the SDN controller connect to every forwarding node in the network or every edge node of the network. We will also illustrate an intelligent SDN controller architecture and provide a companion between our intelligent SDN approach and other SDN approaches including those for open flow and SR networks. Finally, we will outline the current industry trends and standards-based mechanisms that may be combined to provide the intelligent SDN and the gaps that must be filled by standards organizations. |
|||
|
Rethinking Application Aware Network Resource Management in Software Defined Networking |
jiyang liu, Shanghai Jiao Tong University |
|
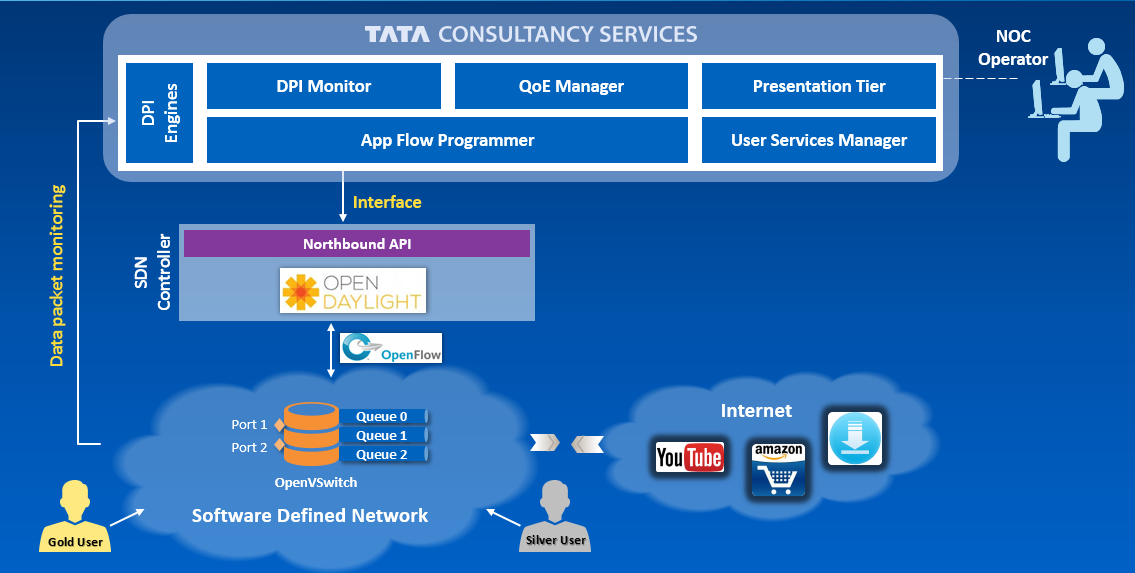
SDN architecture based on separation of control and data plane in network element enables network programmability and application aware networking. In today’s SDN solutions, controllers are able to provide open APIs through service abstraction. For instance, an application is able to invoke connectivity services across multiple domains through a single controller with different service plugins. Application, such as Virtual Tenant Network (VTN) Coordinator, can build virtual network based on underlying physical network. It gets underlying connectivity, or invokes network resources in other words, by deploying a series of flow table entries to physical network through controller. This differs greatly from traditional network management concepts, in which network provision is performed on a dedicated management system either manually, or through the Operation Supporting System (OSS), and is transparent to applications. On the other hand, resource management in today’s SDN implementations is still largely designed for the conventional network management purpose, and the controller is, for the most part, not aware of how applications are using network resources. Given the fact that a large number of applications may be using the network, and each has different service level agreements, in terms of packet loss rate, or availability, it would be of crucial importance to know how each application is using the network. For example, a network failure may disrupt thousands of applications passing the failure point. To realize fast and differentiated failure recovery, we must know precisely the correspondence between the network resources and the affected applications. Another example is the need to temporally reduce/increase the amount of bandwidth allocated for a certain service, e.g., content distribution service. In a network with hundreds, or thousands of network nodes, each containing thousands of flow table entries, traversing the managed topology database for affected flows can be very time and resource consuming, leading to poor scalability. In this work, we are interested in identifying the gap between the current SDN design concept, and true application aware networking resource management. We argue that the current SDN controller implementations are not designed to be fully application aware. We further show that a module that maps the applications to the network resources can help mitigate the problem, and should be designed as a fundamental component in the SDN controller. We use OpenDaylight as a concrete example, and show the performance of typical application aware network operations, e.g., differentiated failure recovery, and application bandwidth adjustment, with and without such a module. Our results shows that in a network configured with 1000 nodes, each with 100 flow table entries, the time to update the flow table entries along a 100 links path is 0.27 seconds and 20.8 seconds, with and without the proposed module, respectively. |
|||
|
SDN Application – An approach to prioritize important Mice flows in a Software Defined Network |
||
Currently Software defined networks is capable of Layer2-4 based policy implementation but is agnostic to higher layers. Application recognition and flow characterization is critical for providing a better Quality of Experience (QoE) to the end user. A simple example could be a Network operator extending better QoE to priority customer for applications being used.
|
|||
|
HANA in SDN: Automatic Numbering and Networking Tool for Initial Setup and Topology Change |
||
Hierarchical and automatic number allocation (HANA) [1][2] is an
Fig. 1. HANA Overview.
|
|||
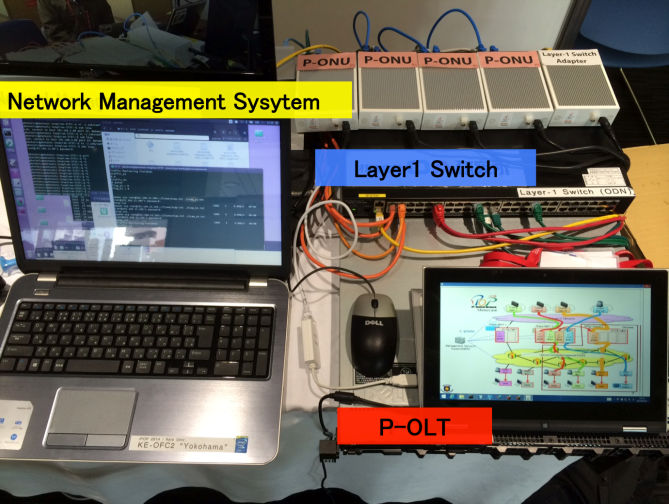
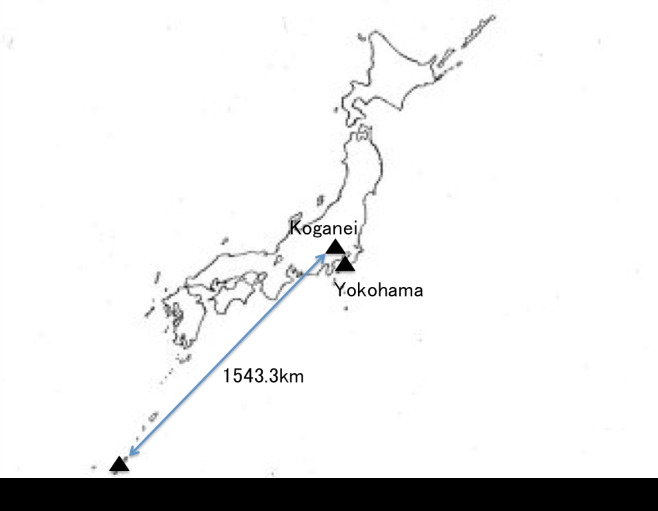
 As a next-generation access and aggregation integrated network, the Elastic Lambda Aggregation Network (EλAN) has been proposed [1]. A programmable optical line terminal (P-OLT) provides logical OLTs (L-OLTs). Each L-OLT is dynamically programmable. Therefore, the L-OLT can act as a virtual OLT (V-OLT). In the EλAN, live migration of V-OLTs among P-OLTs is applied to reduce energy consumption and to enhance network reliability [2]. In the laboratory level, we have successfully demonstrated sequential V-OLT migrations in MPLS/SDN 2013 and SDN/MPLS 2014. In this presentation, we will report V-OLT migration trials over largenetwork environment for evaluating service down time estimation method and also report multiple parallel V-OLT migration trials.
As a next-generation access and aggregation integrated network, the Elastic Lambda Aggregation Network (EλAN) has been proposed [1]. A programmable optical line terminal (P-OLT) provides logical OLTs (L-OLTs). Each L-OLT is dynamically programmable. Therefore, the L-OLT can act as a virtual OLT (V-OLT). In the EλAN, live migration of V-OLTs among P-OLTs is applied to reduce energy consumption and to enhance network reliability [2]. In the laboratory level, we have successfully demonstrated sequential V-OLT migrations in MPLS/SDN 2013 and SDN/MPLS 2014. In this presentation, we will report V-OLT migration trials over largenetwork environment for evaluating service down time estimation method and also report multiple parallel V-OLT migration trials.